مهندسی بینهایت: شزم؛ تجلی قدرت فیزیک در دنیای موسیقی
آیا تاکنون در خصوص سازوکار سرویس تشخیص موسیقی شزم کنجکاو شده اید؟ با توجه به مقاله ی پژوهشی منتشرشده توسط یکی از بنیان گذاران شزم، به نام آوری لی-چون، فرآیندی موسوم به <<شناسایی هویت صوتی>>، پایه ی تمام پردازش های صورت گرفته در پس سرویس شزم محسوب می شود؛ اما شناسایی هویت صوتی به چه مفهوم است؟ با زومیت همراه باشید تا سازوکار شزم را زیر ذره بین قرار دهیم.
برای درک آنچه در این مقالات خواهد آمد، باید به صورت ابتدایی با مفاهیمی همچون پردازش سیگنال آشنا شویم؛ از این رو در ابتدا کار خود را با مفاهیم پایه ای تئوری موسیقی و پردازش سیگنال آغاز می کنیم و با مکانیزم های موجود در بطن شزم، آن را به پایان می رسانیم. برای مطالعه ی این مجموعه ی مقالات به دانشی نیاز نخواهید داشت؛ اما از آنجایی که با علوم کامپیوترو ریاضیات درگیر خواهیم بود، بهتر است که پس زمینه ی علمی مناسبی را به خصوص برای مطالعه ی بخش های پایانی داشته باشید. چنانچه با واژه هایی همچون اُکتاو، فرکانس، نمونه برداری و نشت طیفی آشنایی دارید، می توانید از مطالعه ی بخش اول صرف نظر کنید. شما می توانید از فهرست مطالب برای دسترسی سریع تر به موضوعات استفاده کنید.
موسیقی و فیزیک
صوت، ارتعاش یا موجی است که از طریق هوا یا آب منتشر شده و توسط گوش ادراک می شود؛ به عنوان مثال هنگامی که در حال گوش دادن به موسیقی هستید، هدفون ها ارتعاشاتی را تولید می کنند که تا زمان رسیدن به گوش شما، از طریقهوا منتشر می شوند. از دیدگاه موجی، نور نیز یک ارتعاش محسوب می شود؛ اما به جای گوش، چشم توانایی ادراک آن را دارد. یک ارتعاش را می توان از طریق موج های سینوسی مدل سازی کرد. در این قسمت سعی داریم تا با چگونگی توصیف فیزیکی و فنی موسیقی آشنا شویم.
تن خالص در برابر صوت حقیقی
تن خالص، تُنی با شکل موج سینوسی است، امواج سینوسی توسط مشخصه های زیر توصیف می شود:
- فرکانس موج: تعداد سیکل ها در هر ثانیه با واحد هرتز (Hz)، به عنوان مثال ۱۰۰ هزتر معادل ۱۰۰ سیکل در هر ثانیه است
- دامنه ی موج (مرتبط با بلندی صوت): ابعاد هر سیکل
مشخصه های یادشده توسط گوش انسان در قالب صوت ادراک می شود. گوش انسان در بهترین حالت، تن های خالص با فرکانس ۲۰ تا ۲۰٬۰۰۰ هرتز را می شنود؛ اما این بازه با گذر زمان و افزایش سن انسان، محدودتر می شود. برای مقایسه باید اشاره کنیم که نور از موج های سینوسی با فرکانس بین ۱۰۱۴* ۴ تا ۱۰۱۴* ۷.۹ هرتز تشکیل می شود.
شما می توانید محدوده ی شنوایی خود را با ویدیوی زیر بررسی کنید، این ویدیو، تمام تن های حقیقی بین ۲۰ هرتز تا ۲۰ کیلوهرتز را تولید می کند. من در این ویدیو قادر به شنیدن محدوده ی ۲۰ تا ۱۸ هزار هرتز بودم.
ادراک انسان از بلندی صدا به فرکانس تن خالص بستگی دارد؛ به عنوان مثال، یک تن خالص با دامنه ی ۱۰ و فرکانس ۳۰ هرتز، آرام تر از تن خالص دیگری با دامنه ی ۱۰ و فرکانس ۱۰۰۰ هرتز به گوش می رسد. گوش انسان از یک مدل سایکوآکوستیک تبعیت می کند که دراین مقالهمی توانید، اطلاعات بیش تری را درباره ی آن به دست آورید. در تصویر زیر می توانید نمونه ای از یک موج سینوسی با فرکانس ۲۰ هرتز و دامنه ی یک را مشاهده کنید:
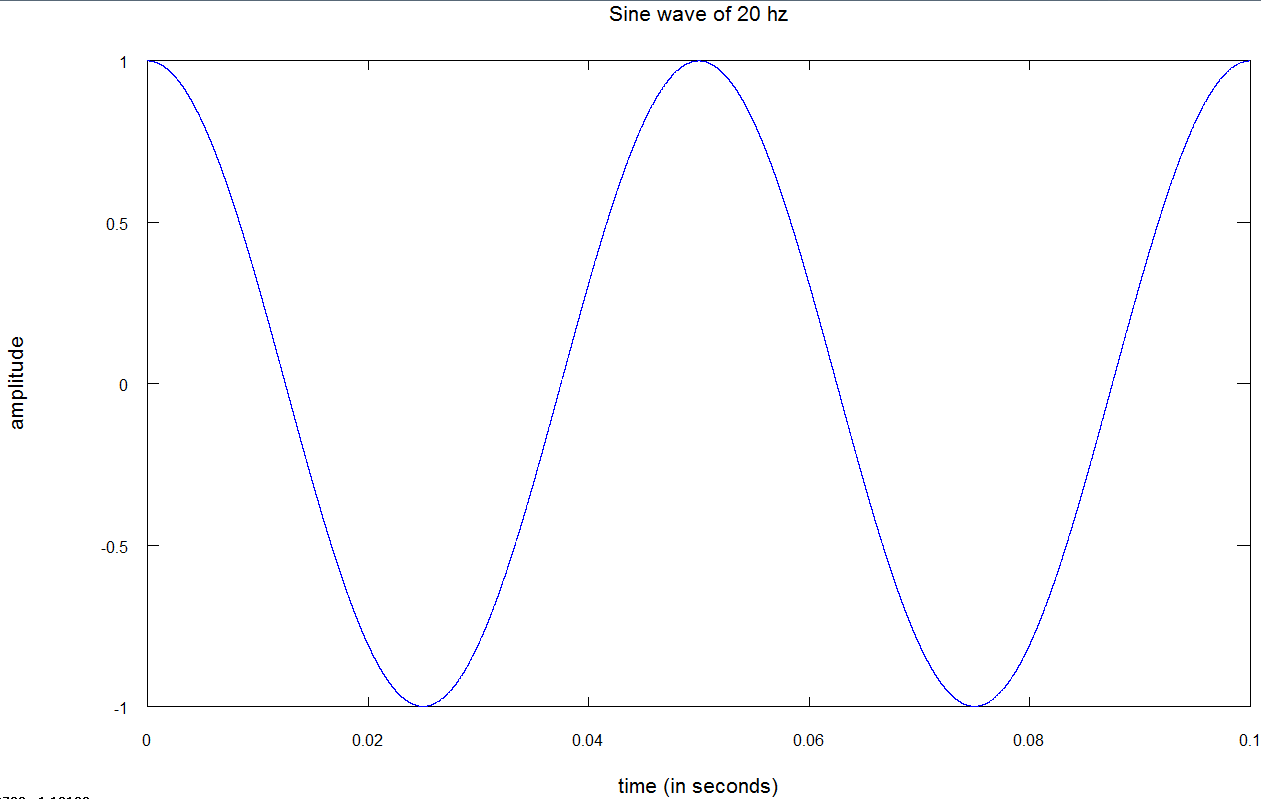
باید بدانید که تن های خالص در دنیای واقعی وجود ندارند و آنچه ما به صورت روزمره می شنویم، ترکیبی از چندین تن خالص با دامنه های متفاوت است.
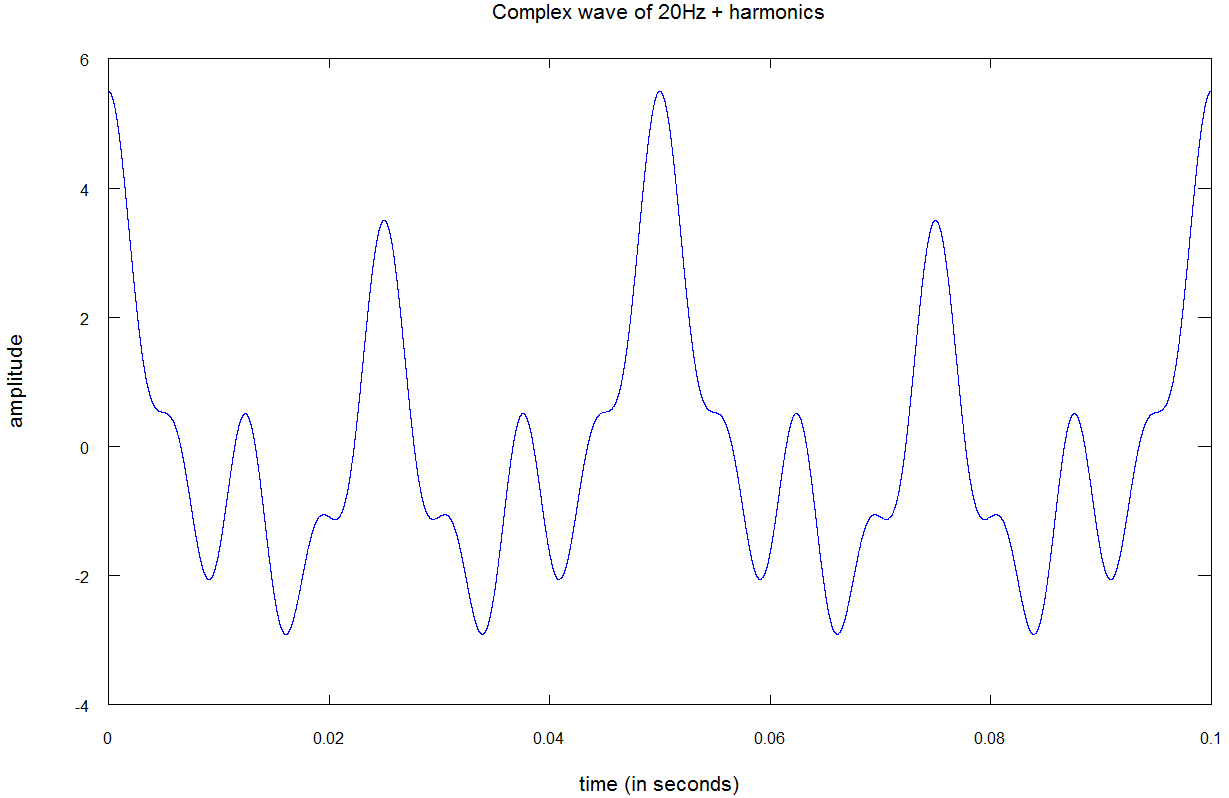
در تصویر بالا می توانید نمونه ای از صدای حقیقی را مشاهده کنید که از ترکیب چندین موج سینوسی شکل گرفته است:
- یک موج سینوسی خالص با فرکانس ۲۰ هرتز و دامنه ی یک؛
- یک موج سینوسی خالص با فرکانس ۴۰ هرتز و دامنه ی ۲؛
- یک موج سینوسیخالص با فرکانس ۸۰ هرتز و دامنه ی ۱.۵؛
- یک موج سینوسی خالص با فرکانس ۱۶۰ هرتز و دامنه ی یک؛
صداهای واقعی می توانند ترکیبی از هزاران تن خالص باشند.
نت های موسیقی
هر قطعه ی موسیقی حاصل مجموعه ای از نت ها است که در زمان به خصوصی اجرا می شوند، هرکدام از این نت ها مدت زمان و بلندی منحصربه فردی دارند.

مجموعه ی نت ها در قالب اکتاو هایی تقسیم می شوند. در کشورهای غربی، هر اکتاو، مجموعه ای از ۸ نت (ای، بی ، سی، دی، ایی، اف، جی در بسیاری از کشورهای انگلیسی زبان و دو - ر - می - فا - سُل - لا - سی در کشورهای لاتین غربی) محسوب می شود. ویژگی اکتاوها بدین شرح است:
- فرکانس هر نت در یک اکتاو در اکتاو بعدی دو برابر می شود؛ به عنوان مثال فرکانسA4(نتAدر اکتاو چهارم) در ۴۴۰ هرتز دو برابر فرکانسA3(نتAدر اکتاو سوم) در ۲۲۰ هرتز بوده و چهار برابر فرکانسA2(نتAدر اکتاو دوم) در ۱۱۰ هرتز است.
بسیاری از آلات موسیقی، بیش از ۸ نت را در اکتاوها فراهم می کنند، چنین نت هایی سِمی تُن یا نیم پرده نامیده می شوند.

برای اکتاو چهارم (یا اکتاو سوم در کشورهای لاتین غربی)، فرکانس نت ها بدین شکل است:
- C4 (Do3)= ۲۶۱.۳ هرتز
- D4 (Re3)= ۲۹۳.۶۷ هرتز
- E4 (Mi3)= ۳۲۹.۶۳ هرتز
- F4 (Fa3)= ۳۴۹.۲۳ هرتز
- G4 (Sol3)= ۳۹۲ هرتز
- A4 (La3)= ۴۴۰ هرتز
- B4 (Si3)= ۴۹۳.۸۸ هرتز
اگرچه ممکن است عجیب به نظر برسد؛ اما حساسیت فرکانسی گوش انسان، لگاریتمی است؛ بدین مفهوم:
- بین ۳۲.۷۰ هرتز و ۶۱.۷۴ هرتز (اکتاو اول)
- یا بین ۲۶۱.۶۳ هرتز و ۴۶۶.۱۶ هرتز (اکتاو چهارم)
- یا بین ۲۰۹۳ هرتزو ۳۹۵۱.۰۷ هرتز (اکتاو هفتم)
گوش های انسان قادر به تشخیص تعداد یکسانی از نت ها هستند. خاطرنشان می کنیم که نت A4/La3در فرکانس ۴۴۰ هرتز، مرجعی استاندارد برای کالیبره سازی ابزار آکوستیک و آلات موسیقی محسوب می شود.
طنین
نواختن یک نت با گیتار، پیانو، ویولون یا یک هنرمند، به تولید صدای یکسانی منجر نمی شود؛ زیرا هر آلت موسیقی، طنین منحصربه فردی برای یک نت دلخواه دارد. برای هر آلت موسیقی،صدای تولیدشده، انبوه فرکانس هایی است که مشابه یک نت دلخواه(نام علمی نت موسیقی،نواکاست)به گوش می رسند. این صدا، یک فرکانسپایه (کم ترین فرکانس) و چندینOvertoneیانت فرعی(هر فرکانسی بالاتر از فرکانس پایه) را در برمی گیرد.
بسیاری از آلت های موسیقی صداهای نزدیک بههارمونیک(همساز) را تولید می کنند. برای چنین ابزارهایی، نت های فرعی، چندین فرکانس پایه با نام هارمونیک هستند؛ به عنوان مثال، ترکیب تن های خالصA2(پایه)،A4وA6هارمونیک هستند؛ اما ترکیب تن های خالصA2،B3وF5غیرهارمونیک یا ناهمساز است. بسیاری از سازهای کوبه ای، مانند درام یا سنج، صداهای غیرهارمونیک تولید می کنند.
خاطرنشان می کنیم که نواک (نت موسیقی ادراک شده)، ممکن است در صدای تولیدشده توسط یک ساز به خصوص وجود نداشته باشد؛ به عنوان مثال، چنانچه یکساز صدایی با تن های خالصA4،A6وA8را تولید کند، مغز انسان صدای حاصل را در قالب یک نتA2تشریح می کند. در حالتی که پایین ترین فرکانس در صداA4باشد، نت / نواک یکA2خواهد بود، به این پدیده،از دست رفتن فرکانس پایهگفته می شود.
طیف نگاره
یک قطعه ی موسیقی توسط چندین ساز و هنرمند نواخته می شود، تمام این سازها، ترکیبی از موج های سینوسی در چندین فرکانس را تولید می کنند و در مجموع، صدای تولیدشده از ترکیب موج های سینوسی به مراتب بزرگ تری تشکیل می شود. می توان با یک طیف نگاره، موسیقی را مشاهده کرد. در اغلب اوقات، طیف نگاره نموداری سه بعدی است:
- زمان روی محور افقیXقرار می گیرد
- فرکانس تن های خالص روی محور عمودیYقرار می گیرد
- بُعد سوم با یک رنگ توصیف می شود و دامنه ی یک فرکانس را در زمان به خصوصی نشان می دهد.
نمودار زیر، طیف نگاره ی مربوط به صدای پیانو را نشان می دهد. رنگ ها در طیف نگاره، دامنه ی صدا را برحسب دسی بل نشان می دهند.
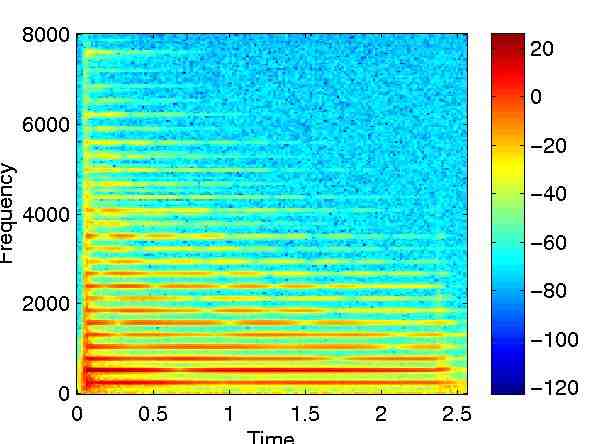
نکته ی جالب توجه دیگر، تغییر شدت فرکانس ها با گذر زمان است، این موضوع یکی دیگر از ویژگی های یک ساز محسوب می شود که آن را منحصربه فرد می کند. اگر نوازنده به جای پیانو، ساز دیگری را بنوازد، الگوی تکامل فرکانس ها متفاوت خواهد بود و صدای حاصل شده نیز کمی تفاوت خواهد داشت؛ زیرا هر هنرمند / ساز، استایل منحصربه فردی دارد. از لحاظ فنی، این تکامل فرکانسی،محدوده ی (envelope)سیگنال صدا را اصلاح می کند و این محدوده بخشی از طنین محسوب می شود.
برای آنکه ایده ای ابتدایی از نوع کارکرد پروسه ی شناسایی هویتصوتی در شزم به دست آورید، توجه شما را به طیف نگاره ی بالا جلب می کنیم که در آن برخی از فرکانس ها (نمونه هایی پایین) اهمیت بیشتری نسبت به بقیه دارند. اگر تنها فرکانس های قدرتمند را نگه داریم، چه پیش می آید؟
دیجیتالی سازی
مادامی که از علاقه مندان به صفحه ی گرامافون نباشید، هنگام گوش دادن به موسیقی از فایل های دیجیتال (mp3، سی دی صوتی،oggیاapple lossless) استفاده می کنید؛ اما هنرمندان موسیقی را به صورت آنالوگ تولید می کنند؛ بدین مفهوم که موسیقی آن ها در قالب بیت نیستند. برای آنکهموسیقی قابل ذخیره سازی یا پخش شدن در دستگاه های الکترونیکی باشد، باید به صورت دیجیتال باشد. در این بخش با چگونگی گذار از آنالوگ به دیجیتال آشنا می شویم. آگاهی از چگونگی تولید موسیقی دیجیتال به ما در بخش های بعدی جهت تحلیل یا دست کاری آن کمک خواهد کرد.
نمونه برداری
سیگنال های آنالوگ پیوسته هستند؛ بدین مفهوم که اگر شما یک ثانیه از سیگنال آنالوگی را انتخاب کنید، می توانید آن را به بی شمار قسمت تقسیم کنید. در دنیای دیجیتال، نمی توان بی نهایت اطلاعات را ذخیره کرد؛ از این رو باید یک واحد حداقلی، نظیر یک میلی ثانیه در اختیار داشته باشید. در طول این واحد از زمان، صوت نمی تواند تغییر کند؛ بنابراین واحد زمان باید به اندازه ای کوتاه باشد که موسیقی دیجیتال شبیه به نمونه ی آنالوگ باشد و به اندازه ای طولانی باشد که بتوان فضای مورد نیاز برای ذخیره ی موسیقی را محدود کرد.
به عنوان مثال، موسیقی مورد علاقه ی خود را به خاطر بیاورید؛ حال تصور کنید که صدا در این موسیقی هر ۲ ثانیه یک بار تغییر کند، بی شک نتیجه ی نهایی هیچ شباهتی به نمونه ی اصلی نخواهد داشت. در چنین شرایطی به لحاظ فنی گفته می شود که صداAliasedشده است؛ این پدیده زمانی رخ می دهد که فرکانس نمونه برداری کمتر از دو برابر فرکانس بیشینه ی موجود در صوت باشد.
برای آنکه از کیفیت صدای موسیقی اطمینان حاصل کنیم، باید واحد نمونه برداری را بسیار کوچک، به عنوان مثال در حد یک نانو ثانیه (۹-۱۰) انتخاب کنیم، در این شرایط کیفیت صدای حاصل بسیار بالا خواهد بود؛ اما فضای کافی برای ذخیره ی موسیقی در اختیار نخواهید داشت. به این فرآیند نمونه برداری گفته می شود.
واحد استاندارد زمان در موسیقی دیجیتال، ۴۴۱۰۰ نموه به ازای هر ثانیه است؛ اما این فرکانس ۴۴.۱ کیلوهرتزی از کجا آمده؟ در فصل نخست، مقاله، گفتیم که انسان در بهترین حالت می تواند اصواتی با فرکانس بین ۲۰ تا ۲۰ هزار هرتز را بشنود. براساس قضیه ی نایکوئیست، برای آنکه بتوان سیگنالی با فرکانس بین صفر تا ۲۰ هزار هرتز را گسسته سازی یا دیجیتال سازی کرد، باید در هر ثانیه حداقل ۴۰ هزار بار نمونه برداری کرد.
ایده ی موجود در پسِ چنین منطقی آن است که برای قابل شناسایی بودن یک سیگنال سینوسی با فرکانسF، باید در هر سیکل آن، حداقل دو نقطه وجود داشته باشد؛ بنابراین چنانچه فرکانس نمونه برداری دو برابر فرکانس سیگنال باشد، در هر سیکل از سیگنال ابتدایی، دو نقطه خواهید داشت. برای درک بهتر موضوع به تصویر زیر توجه کنید:
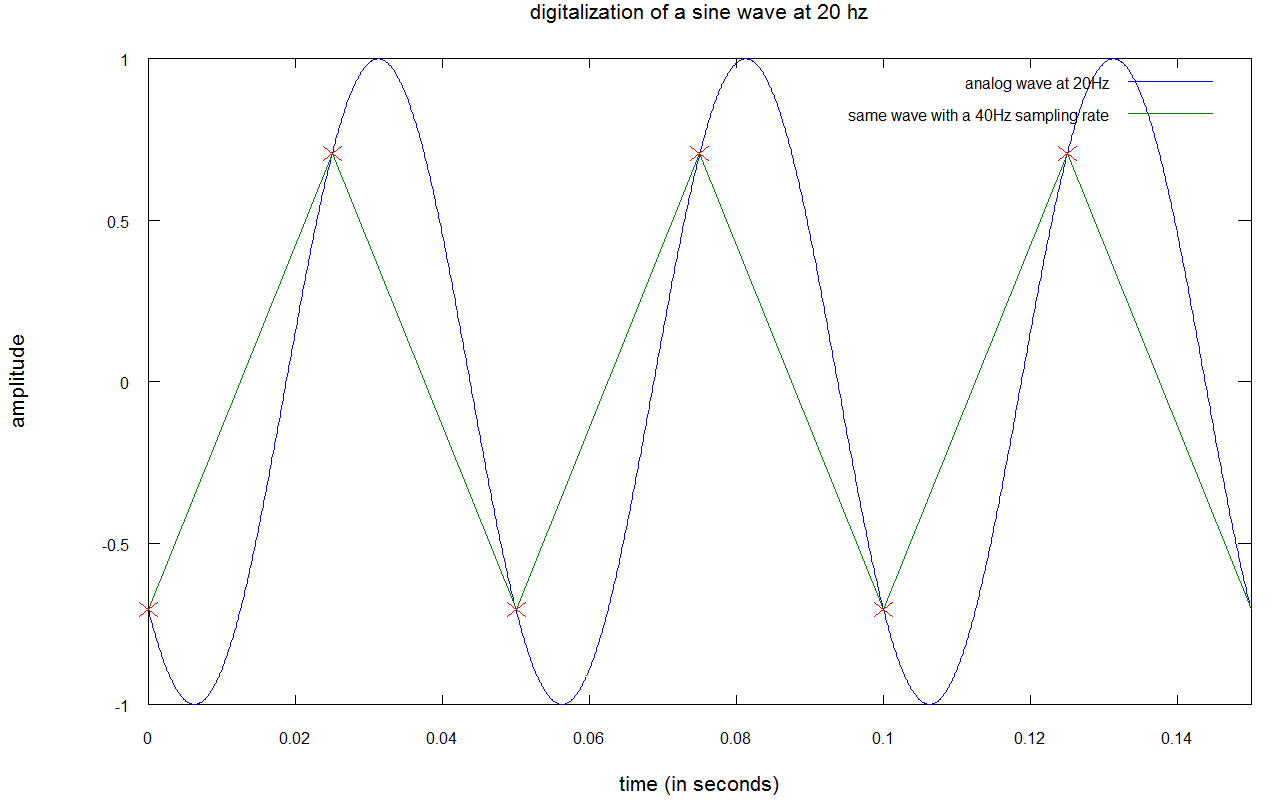
در نمودار بالا، صوتی با فرکانس ۲۰ هرتز با استفاده از نرخ نمونه برداری ۴۰ هرتزی، دیجیتال می شود.
- منحنی آبی، سیگنال صدا را با فرکانس ۲۰ هرتز نشان می دهد
- نقاط قرمز، صداهای نمونه را نشان می دهند، بدین مفهوم که در هر ۱/۴۰ ثانیه، یک بار منحنی آبی را با علامت های ضرب قرمز، نشانه گذاری کرده ایم
- خطوط سبز، درون یابی صدای نمونه برداری شده را به تصویر می کشند
اگرچه خطوط حاصل از نمونه برداری، فُرم یا دامنه ای مشابه منحنی اصلی ندارند؛ امافرکانس سیگنال نمونه برداری شده ثابت باقی مانده است. در ادامه توجه شما را به یک نمونه برداری مناسب جلب می کنیم:
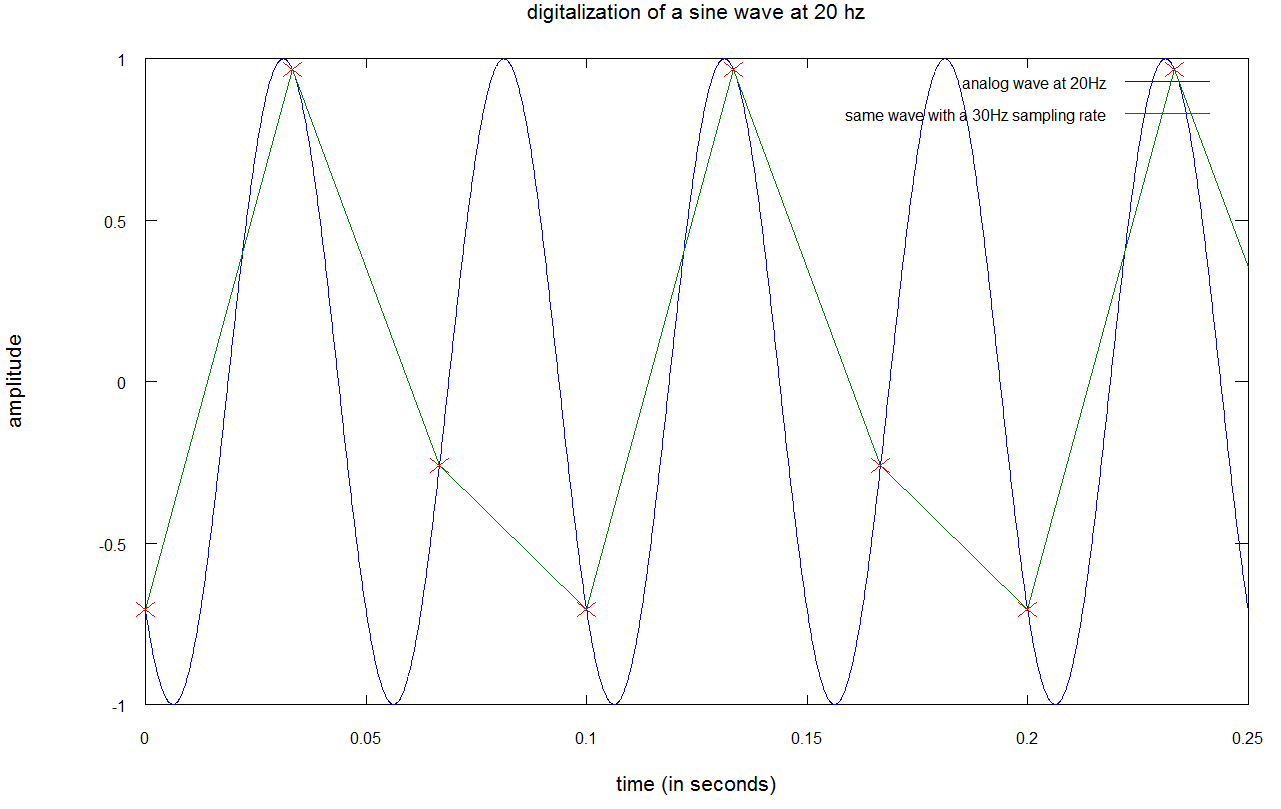
در نمودار بالا صوتی با فرکانس ۲۰ هرتز و سیگنال نمونه برداری شده ای را با فرکانس ۳۰ هرتز مشاهده می کنید؛ بدین مفهوم کهسیگنال نمونه برداری شده فرکانس یکسانی با سیگنال اصلی ندارد: تنها ۱۰ هرتز فاصله وجود دارد. چنانچه دقیق تر نگاه کنید، مشاهده خواهید کرد که یک سیکل در سیگنال نمونه برداری شده، دو سیکل در سیگنال اصلی را به نمایش می گذارد، در این حالت شاهد پدیده یUnder Samplingهستیم.
نمودار بالا، موضوع مهم دیگری را نیز به تصویر می کشد: چنانچه می خواهید سیگنالی بین صفر تا ۲۰ هزار هرتز را دیجیتال کنید، باید پیش از نمونه برداری، فرکانس های بالاتر از ۲۰ هزار هرتز را از سیگنال حذف کنید، در غیر این صورت، فرکانس های یادشده پس از نمونه برداری به فرکانس هایی بین صفر تا ۲۰ هزار هرتز بدل شده و صداهای ناخواسته ای را ایجاد خواهند کرد که به این پدیدهAliasingگفته می شود.
بنابراین، چنانچه می خواهید موسیقی را به خوبی از آنالوگ به دیجیتال تبدیل کنید، باید حداقل نرخ نمونه برداری ۴۰ هزار بار در ثانیه را انتخاب کنید. شرکت هایی همچون سونی در طول دهه ی ۹۰ فرکانس ۴۴.۱ کیلوهرتز را انتخاب کردند؛ زیرا بالاتر از ۴۰ هزار هرتز است و با فرمت های تصویریNTSCوPALسازگاری دارد؛ البته استانداردهای دیگری همچون ۴۸ کیلوهرتز (بلوری)، ۹۶ کیلوهرتز یا ۱۹۲ کیلوهرتز نیز وجود دارند؛ اما چنانچه حرفه ای یا به اصطلاح خوره ی صدا نیستید، به احتمال زیاد، موسیقی را با نرخ ۴۴.۱ کیلوهرتز گوش می دهید.
نکته ی ۱: قضیه ی نایکوئیست مبحثبسیار گسترده ای است، برای کسب اطلاعات بیشتر می توانید به مراجع پردازش سیگنال یا صفحه ی ویکیپدیای این قضیه مراجعه کنید.
نکته ی ۲: برای دیجتالی سازی، فرکانس نمونه برداری بایداکیدابزرگتر از دو برابر فرکانس سیگنال باشد؛ زیرا در بدترین حالت، ممکن است با یک سیگنال دیجیتالی ثابت طرف باشیم.
کوانتیده سازی
در بخش قبل، با چگونگی دیجیتالی سازی فرکانس های موسیقی آنالوگ آشنا شدیم؛ اما بلندی صدای موسیقی چگونه خواهد بود؟ بلندی صدا معیاری نسبی است: به ازای بلندی صدای یکسان درون سیگنال، چنانچه حجم صدای اسپیکر را افزایش دهید، شدت صدای موسیقی افزایش خواهد یافت. بلندی صدا، به تفاوت بین پایین ترین و بالاترین سطح صدا در یک قطعه ی موسیقی گفته می شود.
مشکل پیشین در مورد بلندی صدا نیز پیش می آید: گذار از دنیای پیوسته با بی نهایت تغییر در حجم به دنیای گسسته چگونه صورت می گیرد؟
موسیقی مورد علاقه ی خود را با چهار سطح بلندی <<بدون صدا>>، <<صدای پایین>>، <<صدای بلند>> و <<تمام توان>> تصور کنید، در چنین وضعیتی، حتی بهترین موسیقی دنیا نیز غیرقابل تحمل خواهد بود. آنچه تصور کردید، کوانتیده سازی با ۴ سطح بود. در تصور زیر می توانید نمونه ای از کوانتیده سازی سطح پایین را مشاهده کنید:
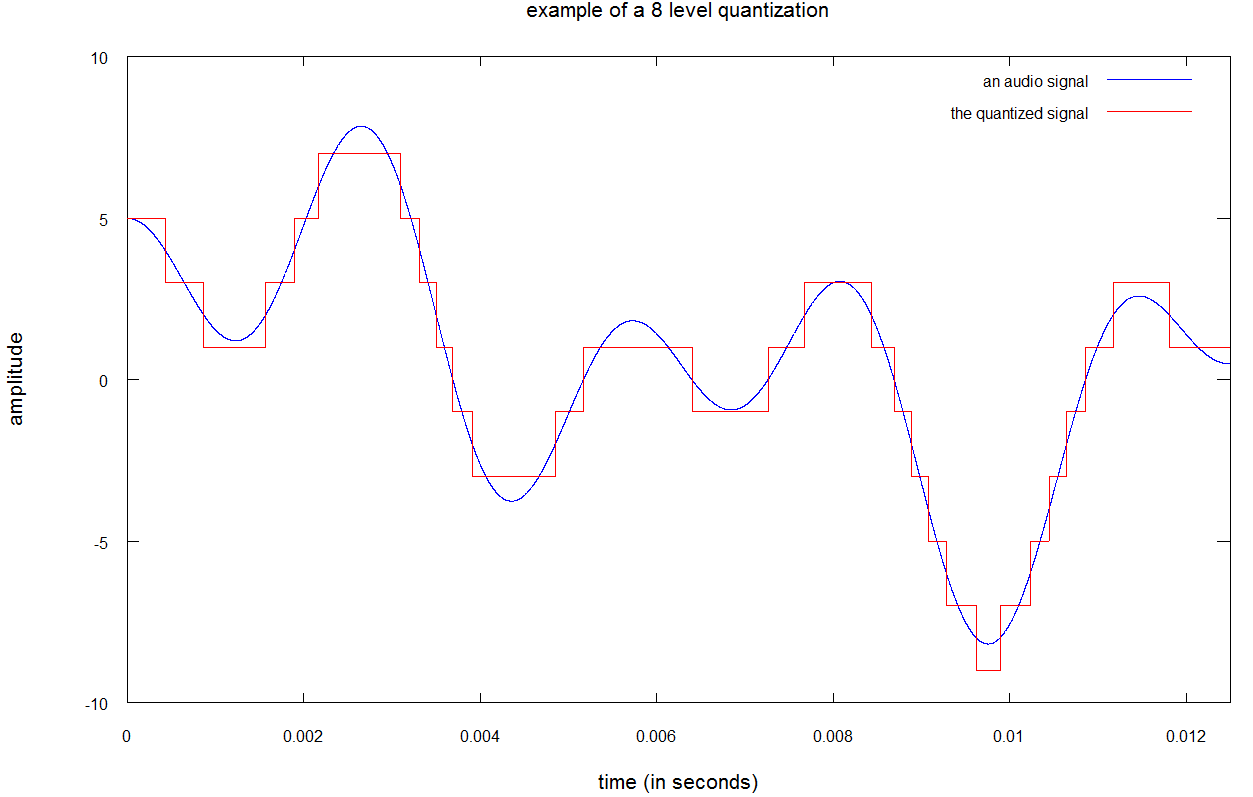
این تصویر، کوانتیده سازی با ۸ سطح را نشان می دهد. همان طور که مشاهده می کنید، صدای حاصل با رنگ قرمز، تفاوت فاحشی با نمونه ی اصلی دارد. تفاوت بین صدای واقعی و نمونه ی کوانتیده شده،خطای کوانتیده سازییانویز کوانتیده سازینامیده می شود. کوانتیده سازی ۸ سطحی با نام کوانتیده سازی ۳ بیتی نیز نامیده می شود؛ زیرا شما تنها به ۳ بیت برای پیاده سازی ۸ سطح مختلف نیاز خواهید داشت (۸ = ۲۳).
در تصویر زیر همان سیگنال را با کوانتیده سازی ۶۴ سطحی یا کوانتیده سازی ۶ بیتی مشاهده می کنید. اگرچه صدای حاصل باز هم متفاوت به نظر می رسد؛ اما شباهت بیشتری به صدای اصلی دارد.
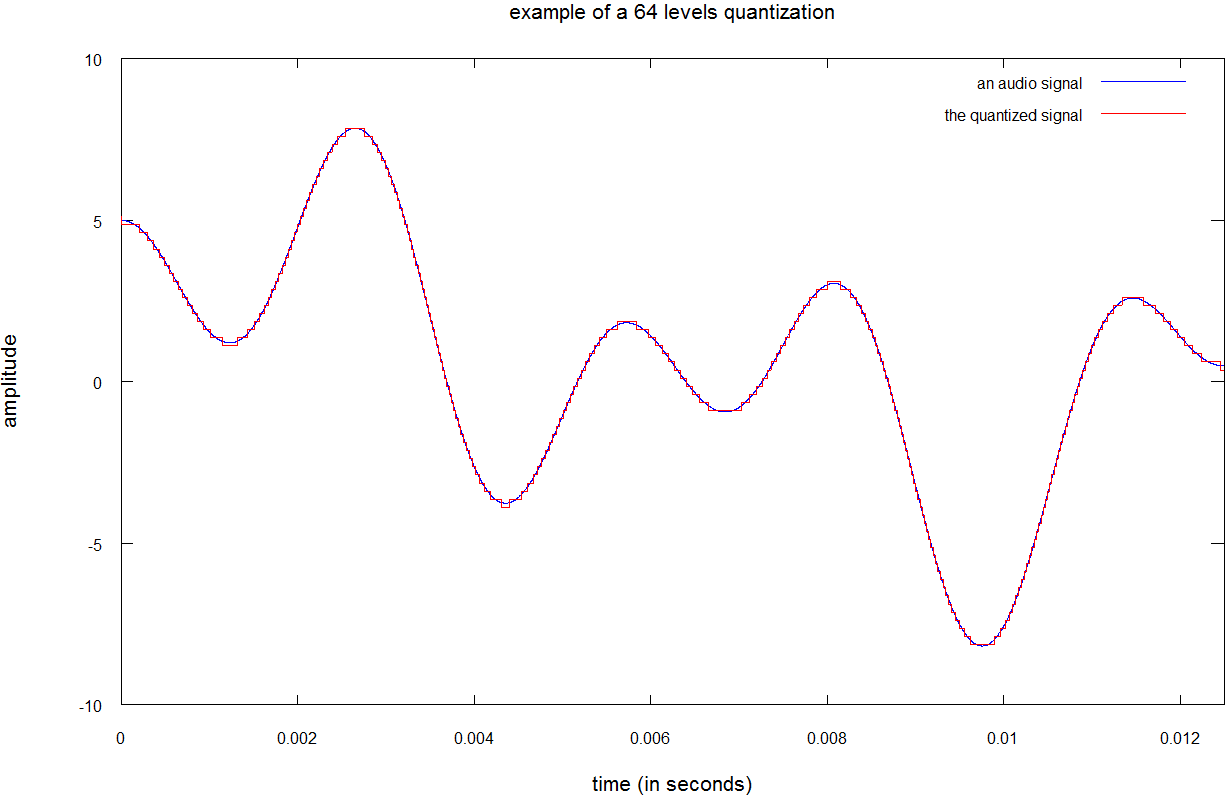
خوشبختانه گوش انسان ها حساسیت فوق العاده بالایی ندارد؛ از این روکوانتیده سازی ۱۶ بیتی یا ۶۵۵۳۶ سطحیبه عنوان استاندارد تعریف می شود. با کوانتیده سازی ۱۶ بیتی، نویز کوانتیده سازی برای گوش انسان ها به اندازه ی کافی در سطح پایینی قرار دارد.
نکته ی ۱: در استودیوهای ضبط موسیقی، حرفه ای ها از کوانتیده سازی ۲۴ بیتی استفادهمی کنند؛ بدین مفهوم که بین بالاترین و پایین ترین بلندی صدا، ۲۲۴یا ۱۶ میلیون تغییر ممکن وجود دارد.
نکته ی ۲: در مثال های ارائه شده در خصوص تعداد سطح های کوانتیده سازی، تقریب هایی صورت گرفته است.
مدولاسیون کُد پالس
PCMیا مدولاسیون کُد پالس، استانداردی است که سیگنال های دیجیتال را به تصویر می کشد. این استاندارد در دیسک های فشرده و بسیاری از دستگاه های الکترونیکی به کار می رود؛ به عنوان مثال، هنگامی که به یک فایلmp3در کامیپوتر، گوشی هوشمند یا تبلت خود گوش می دهید، آن فایل به صورت خودکار به سیگنالPCMتبدیل شده و به هدفون شما ارسال می شود.
جریانPCM، جریانی از بیت های سازمان دهی شده است، این جریان می تواند از چندین کانال تشکیل شده باشد؛ به عنوان مثال، یک قطعه ی موسیقی استریو، دو کانال دارد. در یک جریان، دامنه ی سیگنال به نمونه هایی تقسیم می شود. تعداد نمونه ها به ازای هر ثانیه، با نرخ نمونه برداری موسیقی هماهنگی دارد؛ به عنوان مثال، یک قطعه ی موسیقی با نرخ نمونه برداری ۴۴۱۰۰ هرتزی، در هر ثانیه ۴۴۱۰۰ نمونه خواهد داشت. هر نمونه، دامنه ی صدای کوانتیده ی مربوط به کسری از ثانیه ها را در بر دارد.
فرمت هایPCMگوناگونی وجود دارد؛ اما رایج ترین نمونه برای صدا، فرمت خطیPCMاستریو با فرکانس ۴۴.۱ کیلوهرتز و عمق ۱۶ بیت است، این فرمت ۴۴۱۰۰ نمونه در هر ثانیه از موسیقی را در بر دارد و هر نمونه، ۴ بیت را اشغال می کنند.
- ۲ بایت (۱۶ بیت) برای شدتصدای (از ۳۲٬۷۶۸- تا ۳۲٬۷۶۷) اسپیکر سمت چپ
- ۲ بایت (۱۶ بیت) برای شدت صدای (از ۳۲٬۷۶۸- تا ۳۲٬۷۶۷) اسپیکر سمت راست

در فرمت استریویPCMبا فرکانس ۴۴.۱ کیلوهرتز و عمق ۱۶ بیت، در هر ثانیه از موسیقی، ۴۴۱۰۰ نمونه مانند تصویر بالا خواهید داشت.
از صدای دیجیتال تا فرکانس
شما اکنون از چگونگی گذار از صدای آنالوگ به
برچسب: ،